
一、使用Insert...Values语句写入数据
之前主要使用的是关系数据库,那么写入数据最先想到的就是Insert语句了,在Hive中也可以使用Insert语句来写入数据。假设需要向usr表中写入5条数据,可以执行下面的步骤。
获取更多Hadoop、HDFS、HBase、MapReduce、YARN、Hive等等技术内容,可访问Hadoop大数据技术专栏。
1. 创建表usr
create table if not exists usr(id bigint, name string, age int);


2. 插入数据记录
insert into usr values(1, 'Rickie', 20);
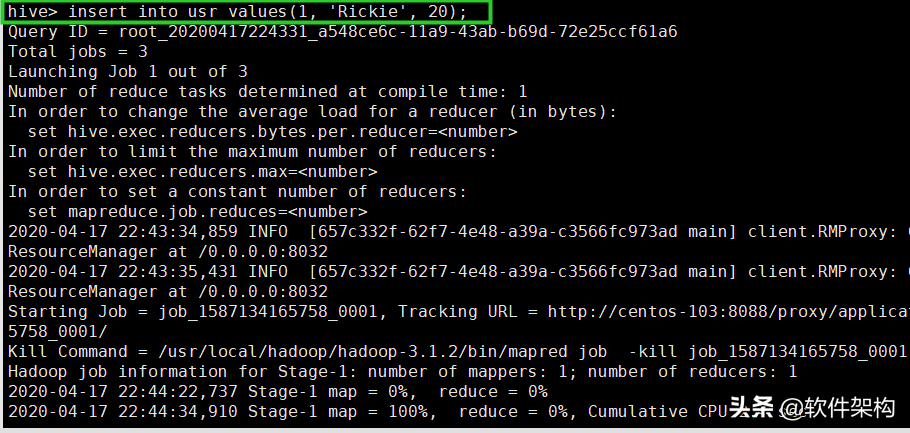
正常可以看到下面的结果输出,说明在执行insert...values语句时,底层是在执行MapReduce作业。
hive> insert into usr values(1, 'Rickie', 20);
Query ID = root_20200417224331_a548ce6c-11a9-43ab-b69d-72e25ccf61a6
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
2020-04-17 22:43:34,859 INFO [657c332f-62f7-4e48-a39a-c3566fc973ad main] client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2020-04-17 22:43:35,431 INFO [657c332f-62f7-4e48-a39a-c3566fc973ad main] client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Starting Job = job_1587134165758_0001, Tracking URL = http://centos-103:8088/proxy/application_1587134165758_0001/
Kill Command = /usr/local/hadoop/hadoop-3.1.2/bin/mapred job -kill job_1587134165758_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2020-04-17 22:44:22,737 Stage-1 map = 0%, reduce = 0%
2020-04-17 22:44:34,910 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.4 sec
2020-04-17 22:44:47,879 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 4.47 sec
MapReduce Total cumulative CPU time: 4 seconds 470 msec
Ended Job = job_1587134165758_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://centos-103:9000/user/hive/warehouse/hivedb.db/usr/.hive-staging_hive_2020-04-17_22-43-31_459_2394264050809447103-1/-ext-10000
Loading data to table hivedb.usr
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 4.47 sec HDFS Read: 16630 HDFS Write: 273 SUCCESS
Total MapReduce CPU Time Spent: 4 seconds 470 msec
OK
Time taken: 78.64 seconds
访问Spring Cloud技术专栏,了解更多的技术细节和项目代码。
3. 查看数据
此时,在windows上使用HDFS的WebUI,通过 Utilities-->Browse the file system 进入到 /user/hive/warehouse/hivedb.db/usr 目录下,可以看到数据库文件:000000_0。
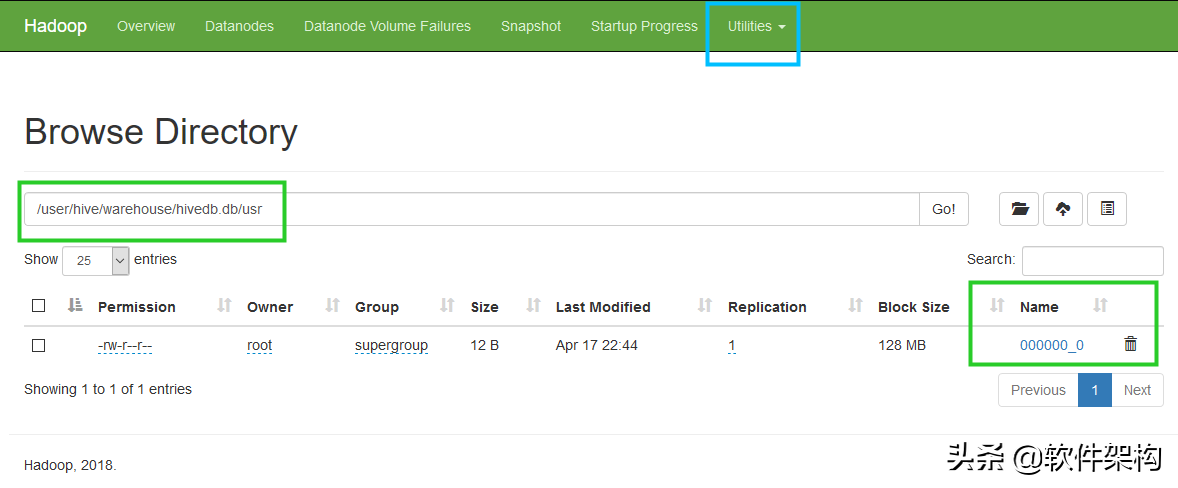
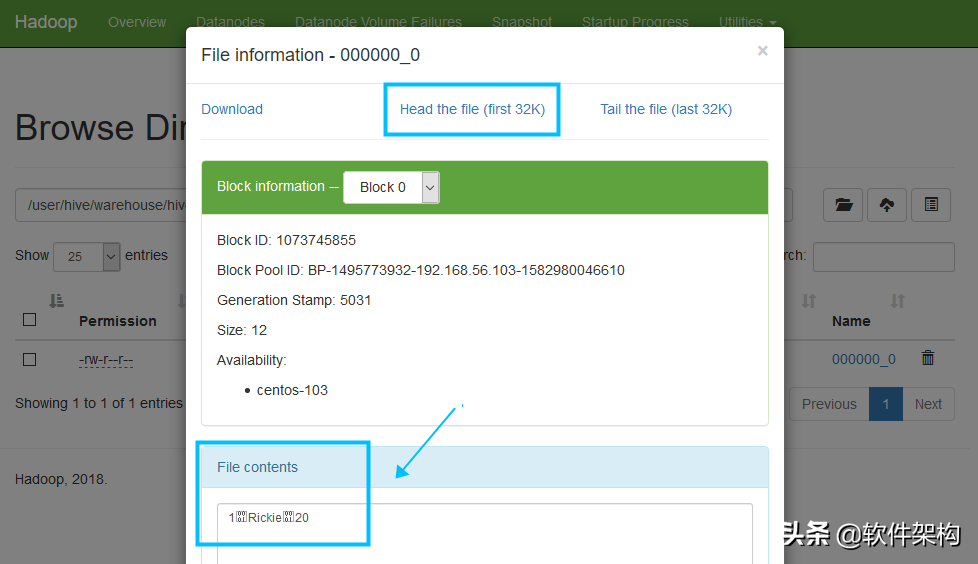
可以进一步查看文件中的内容,就是前面通过insert...values命令插入的数据记录。
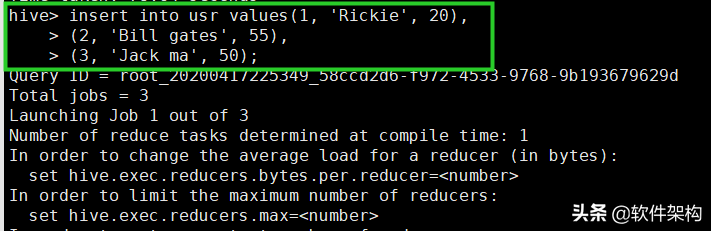
再次执行insert语句,然后使用select语句,可以轻松查看到写入的内容:
hive> insert into usr values(1, 'Rickie', 20),
> (2, 'Bill gates', 55),
> (3, 'Jack ma', 50);
select * from usr;

再次进入webUI,刷新浏览器,会看到目录变成了如下这样:
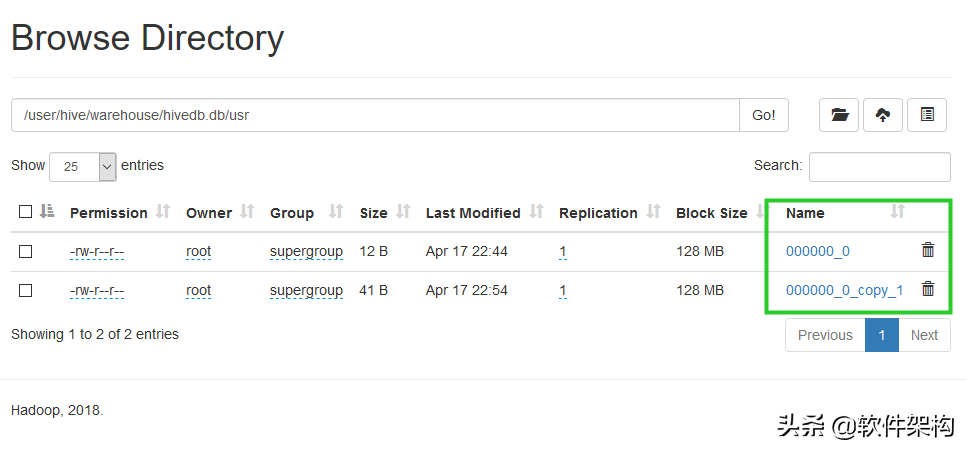
每次执行Insert语句(底层执行MapReduce任务)都会生成独立的数据文件。对于HDFS来说,优势是存储少量大文件,不是存储大量小文件。
获取更多Elasticsearch设计细节和演示项目源代码,可访问Elasticsearch 7.x 技术专栏。
二、使用Load语句写入数据
除了使用insert语句以外,还可以通过load语句来将文件系统的数据写入到数据库表中。删除刚才创建的表,然后使用下面的语句重新创建:
create table if not exists usr(id bigint, name string, age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
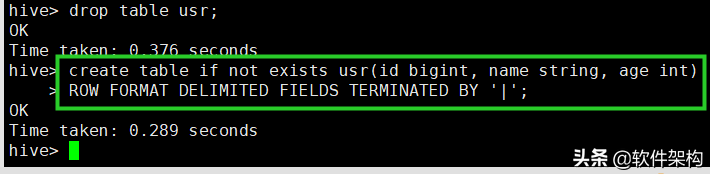
上面最重要的一句就是ROW FORMAT DELIMITED FIELDS TERMINATED BY '|',说明表的字段由符号“|”进行分隔。
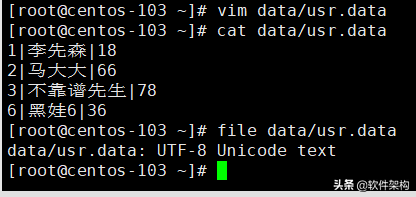
然后准备要导入的文件:usr.data。
1|李先森|18
2|马大大|66
3|不靠谱先生|78
6|黑娃6|36
因为usr.data中包含有中文,确保文件格式是utf-8(GB2312导入后会有乱码)。
在vim中直接进行转换文件编码,比如将一个文件转换成utf-8格式,命令如下:
:set fileencoding=utf-8
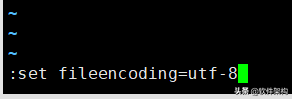
查看文件编码file命令
file data/usr.data
然后执行下面的命令进行导入:
load data local inpath '/root/data/usr.data' into table usr;
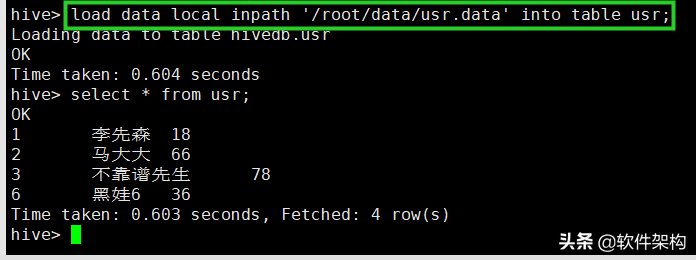
你会发现使用load语句写入数据比insert语句要快许多倍,因为Hive并不对scheme进行校验,仅仅是将数据文件挪到HDFS系统上,也没有执行MapReduce作业。所以从导入数据的角度而言,使用load要优于使用insert...values。
三、使用Insert ... Select语句写入数据
使用insert...select语句将数据从usr表转移到person表:
insert into table person select * from usr;
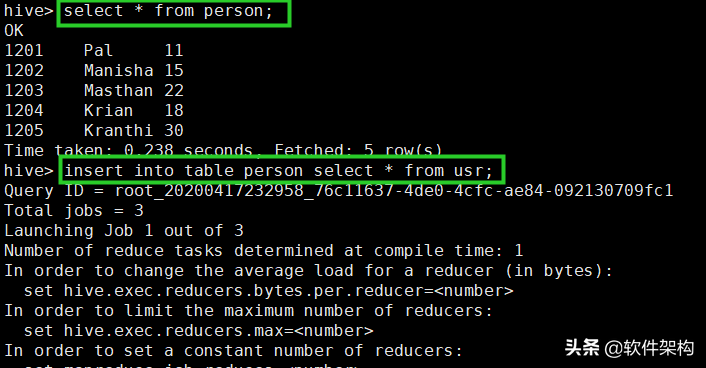
注意:insert...select语句底层也会执行一个MapReduce作业,速度会比较慢。
至此,关于Hive读时模式(schema on read),以及使用命令行对Hive进行数据导入的介绍就到这里了。
四、查看Hive的执行计划:
hive> explain insert into usr values(1, 'Rickie', 22);
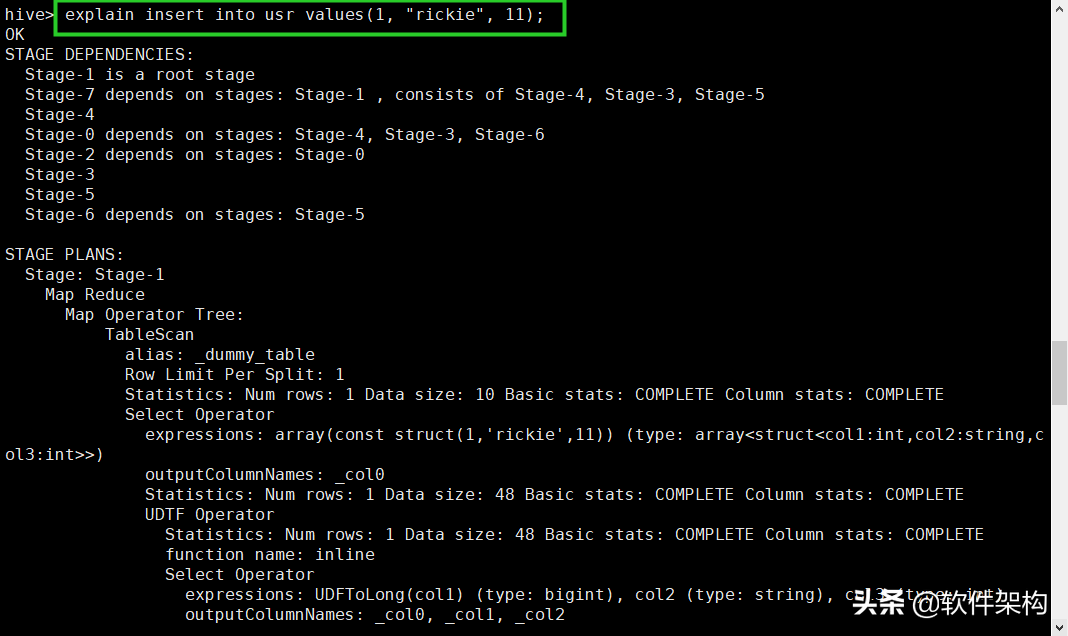
Hive的执行要转化成若干步map-reduce的过程,而且可能要在多个节点间通信,所以即便很少的数据可能也是费了半天劲才执行出来的。也就是说Hive是为了处理大数据的,对于小数据的处理并不是优势。
相关推荐
-
进入hadoop安装目录(hadoop的安装与配置详细过程)
Hadoop是Apache基金会面向全球开源的产品之一,任何用户都可以从Apache Hadoop 官网下载使用。今天,播妞将以编写时较为稳定的Hadoop2.7.4版本为例,详细讲解Hadoop的安装。 先将下载的hadoop-2.7.4.tar.gz安装包上...
-
hadoop集群的搭建步骤(hadoop怎么集群部署)
第一步:搭建配置新的虚拟机 格式化之前先把tmp目录下所有与Hadoop有关的信息全部删除 rm -rf /tmp/hadoop-centos* 开启之后jps只有Java的进程:sudo vi /etc/hosts 里面加 bogon 1.sudo赋权 Root用户 vi /etc/sudoe...
-
etl常见的调度工具(Etl调度)
1.区别ETL作业调度工具和任务流调度工具kettle是一个ETL工具,ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)。kettle中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后...
-
hive存储格式和压缩格式(hive的压缩格式)
hive表的存储格式有 TEXTFILE SEQUENCEFILE (三种压缩选择:NONE, RECORD, BLOCK。 Record压缩率低,一般建议使用BLOCK压缩) RCFILE ORC 自定义格式 hive表存储格式是表自身的存储结构,内部涉及存储数据的结构,...