
本节将详细介绍C语言的基本数据类型,包括如何声明变量、如何表示字面值常量(如,5或2.78),以及典型的用法。
一些老式的C语言编译器无法支持这里提到的所有类型,请查阅你使用的编译器文档,了解可以使用哪些类型。
3.4.1 int类型
C语言提供了许多整数类型,为什么一种类型不够用?因为C语言让程序员针对不同情况选择不同的类型。特别是,C语言中的整数类型可表示不同的取值范围和正负值。一般情况使用int类型即可,但是为满足特定任务和机器的要求,还可以选择其他类型。
int类型是有符号整型,即int类型的值必须是整数,可以是正整数、负整数或零。其取值范围依计算机系统而异。一般而言,储存一个int要占用一个机器字长。因此,早期的16位IBM PC兼容机使用16位来储存一个int值,其取值范围(即int值的取值范围)是-32768~32767。目前的个人计算机一般是32位,因此用32位储存一个int值。现在,个人计算机产业正逐步向着64位处理器发展,自然能储存更大的整数。ISO C规定int的取值范围最小为-32768~32767。一般而言,系统用一个特殊位的值表示有符号整数的正负号。第15章将介绍常用的方法。
1.声明int变量
第2章中已经用int声明过基本整型变量。先写上int,然后写变量名,最后加上一个分号。要声明多个变量,可以单独声明每个变量,也可在int后面列出多个变量名,变量名之间用逗号分隔。下面都是有效的声明:
int erns;
int hogs, cows, goats;可以分别在4条声明中声明各变量,也可以在一条声明中声明4个变量。两种方法的效果相同,都为4个int大小的变量赋予名称并分配内存空间。
以上声明创建了变量,但是并没有给它们提供值。变量如何获得值?前面介绍过在程序中获取值的两种途径。第1种途径是赋值:
cows = 112;第2种途径是,通过函数(如,scanf())获得值。接下来,我们着重介绍第3种途径。
2.初始化变量
初始化(initialize)变量就是为变量赋一个初始值。在C语言中,初始化可以直接在声明中完成。只需在变量名后面加上赋值运算符(=)和待赋给变量的值即可。如下所示:
int hogs = 21;
int cows = 32, goats = 14;
int dogs, cats = 94; /* 有效,但是这种格式很糟糕 */以上示例的最后一行,只初始化了cats,并未初始化dogs。这种写法很容易让人误认为dogs也被初始化为94,所以最好不要把初始化的变量和未初始化的变量放在同一条声明中。
简而言之,声明为变量创建和标记存储空间,并为其指定初始值(如图3.4所示)。
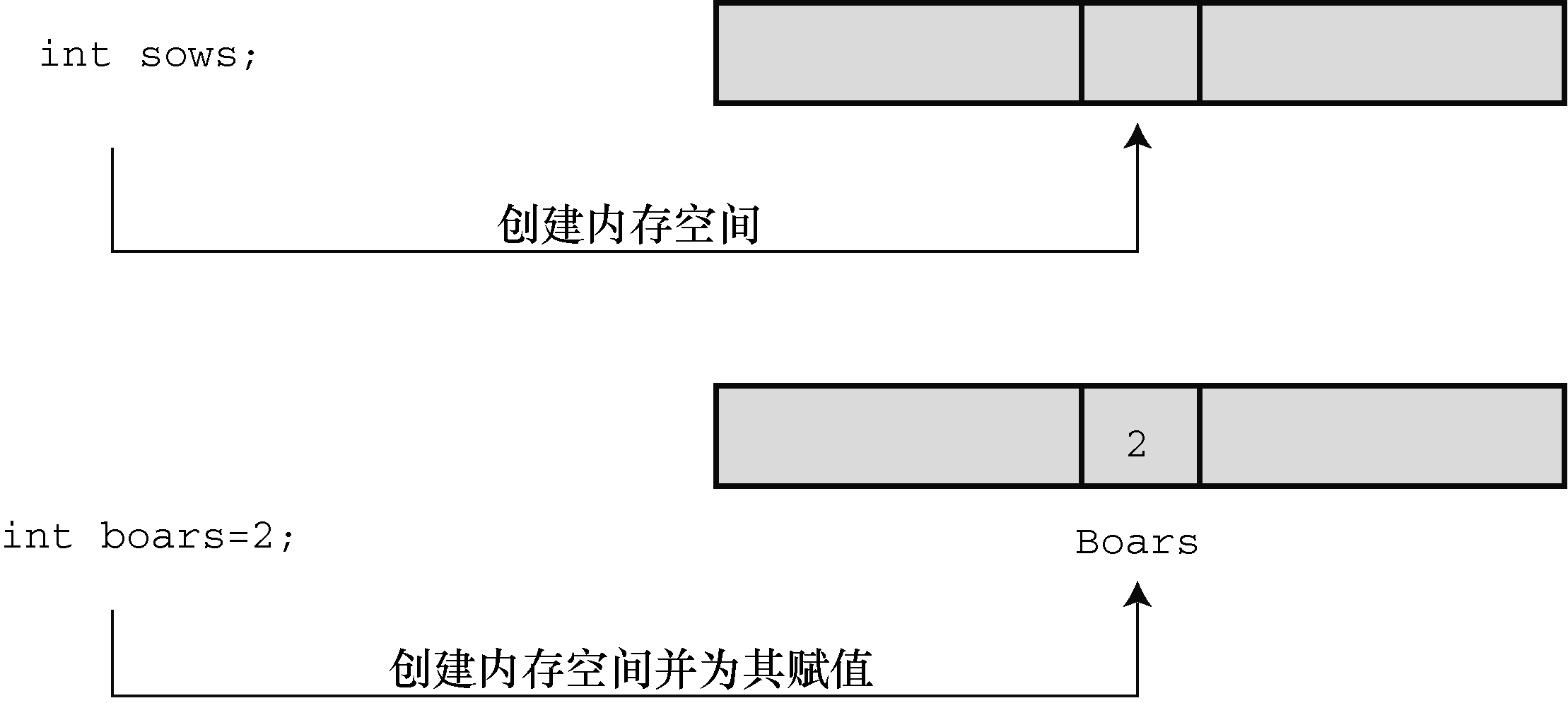

图3.4 定义并初始化变量
3.int类型常量
上面示例中出现的整数(21、32、14和94)都是整型常量或整型字面量。C语言把不含小数点和指数的数作为整数。因此,22和-44都是整型常量,但是22.0和2.2E1则不是。C语言把大多数整型常量视为int类型,但是非常大的整数除外。详见后面“long常量和long long常量”小节对long int类型的讨论。
4.打印int值
可以使用printf()函数打印int类型的值。第2章中介绍过,%d指明了在一行中打印整数的位置。%d称为转换说明,它指定了printf()应使用什么格式来显示一个值。格式化字符串中的每个%d都与待打印变量列表中相应的int值匹配。这个值可以是int类型的变量、int类型的常量或其他任何值为int类型的表达式。作为程序员,要确保转换说明的数量与待打印值的数量相同,编译器不会捕获这类型的错误。程序清单3.2演示了一个简单的程序,程序中初始化了一个变量,并打印该变量的值、一个常量值和一个简单表达式的值。另外,程序还演示了如果粗心犯错会导致什么结果。
程序清单3.2 print1.c程序
/* print1.c - 演示printf()的一些特性 */
#include <stdio.h>
int main(void)
{
int ten = 10;
int two = 2;
printf("Doing it right: ");
printf("%d minus %d is %dn", ten, 2, ten - two);
printf("Doing it wrong: ");
printf("%d minus %d is %dn", ten); // 遗漏2个参数
return 0;
}编译并运行该程序,输出如下:
Doing it right: 10 minus 2 is 8
Doing it wrong: 10 minus 16 is 1650287143在第一行输出中,第1个%d对应int类型变量ten;第2个%d对应int类型常量2;第3个%d对应int类型表达式ten - two的值。在第二行输出中,第1个%d对应ten的值,但是由于没有给后两个%d提供任何值,所以打印出的值是内存中的任意值(读者在运行该程序时显示的这两个数值会与输出示例中的数值不同,因为内存中储存的数据不同,而且编译器管理内存的位置也不同)。
你可能会抱怨编译器为何不能捕获这种明显的错误,但实际上问题出在printf()不寻常的设计。大部分函数都需要指定数目的参数,编译器会检查参数的数目是否正确。但是,printf()函数的参数数目不定,可以有1个、2个、3个或更多,编译器也爱莫能助。记住,使用printf()函数时,要确保转换说明的数量与待打印值的数量相等。
5.八进制和十六进制
通常,C语言都假定整型常量是十进制数。然而,许多程序员很喜欢使用八进制和十六进制数。因为8和16都是2的幂,而10却不是。显然,八进制和十六进制记数系统在表达与计算机相关的值时很方便。例如,十进制数65536经常出现在16位机中,用十六进制表示正好是10000。另外,十六进制数的每一位的数恰好由4位二进制数表示。例如,十六进制数3的二进制数是0011,十六进制数5是的二进制数0101。因此,十六进制数35的位组合(bit pattern)是00110101,十六进制数53的位组合是01010011。这种对应关系使得十六进制和二进制的转换非常方便。但是,计算机如何知道10000是十进制、十六进制还是二进制?在C语言中,用特定的前缀表示使用哪种进制。0x或0X前缀表示十六进制值,所以十进制数16表示成十六进制是0x10或0X10。与此类似,0前缀表示八进制。例如,十进制数16表示成八进制是020。第15章将更全面地介绍进制相关的内容。
要清楚,使用不同的进制数是为了方便,不会影响数被储存的方式。也就是说,无论把数字写成16、020或0x10,储存该数的方式都相同,因为计算机内部都以二进制进行编码。
6.显示八进制和十六进制
在C程序中,既可以使用也可以显示不同进制的数。不同的进制要使用不同的转换说明。以十进制显示数字,使用%d;以八进制显示数字,使用%o;以十六进制显示数字,使用%x。另外,要显示各进制数的前缀0、0x和0X,必须分别使用%#o、%#x、%#X。程序清单3.3演示了一个小程序(回忆一下,在某些集成开发环境(IDE)下编写的代码中插入getchar();语句,程序在执行完毕后不会立即关闭执行窗口)。
程序清单3.3 bases.c程序
/* bases.c--以十进制、八进制、十六进制打印十进制数100 */
#include <stdio.h>
int main(void)
{
int x = 100;
printf("dec = %d; octal = %o; hex = %xn", x, x, x);
printf("dec = %d; octal = %#o; hex = %#xn", x, x, x);
return 0;
}编译并运行该程序,输出如下:
dec = 100; octal = 144; hex = 64
dec = 100; octal = 0144; hex = 0x64该程序以3种不同记数系统显示同一个值。printf()函数做了相应的转换。注意,如果要在八进制和十六进制值前显示0和0x前缀,要分别在转换说明中加入#。
3.4.2 其他整数类型
初学C语言时,int类型应该能满足大多数程序的整数类型需求。尽管如此,还应了解一下整型的其他形式。当然,也可以略过本节跳至3.4.3节阅读char类型的相关内容,以后有需要时再阅读本节。
C语言提供3个附属关键字修饰基本整数类型:short、long和unsigned。应记住以下几点。
- short int类型(或者简写为short)占用的存储空间可能比int类型少,常用于较小数值的场合以节省空间。与int类似,short是有符号类型。
- long int或long占用的存储空间可能比int多,适用于较大数值的场合。与int类似,long是有符号类型。
- long long int或long long(C99标准加入)占用的储存空间可能比long多,适用于更大数值的场合。该类型至少占64位。与int类似,long long是有符号类型。
- unsigned int或unsigned只用于非负值的场合。这种类型与有符号类型表示的范围不同。例如,16位unsigned int允许的取值范围是0~65535,而不是-32768~32767。用于表示正负号的位现在用于表示另一个二进制位,所以无符号整型可以表示更大的数。
- 在C90标准中,添加了unsigned long int或unsigned long和unsigned short int或unsigned short类型。C99标准又添加了unsigned long long int或unsigned long long。
- 在任何有符号类型前面添加关键字signed,可强调使用有符号类型的意图。例如,short、short int、signed short、signed short int都表示同一种类型。
1.声明其他整数类型
其他整数类型的声明方式与int类型相同,下面列出了一些例子。不是所有的C编译器都能识别最后3条声明,最后一个例子所有的类型是C99标准新增的。
long int estine;
long johns;
short int erns;
short ribs;
unsigned int s_count;
unsigned players;
unsigned long headcount;
unsigned short yesvotes;
long long ago;2.使用多种整数类型的原因
为什么说short类型“可能”比int类型占用的空间少,long类型“可能”比int类型占用的空间多?因为C语言只规定了short占用的存储空间不能多于int,long占用的存储空间不能少于int。这样规定是为了适应不同的机器。例如,过去的一台运行Windows 3.x的机器上,int类型和short类型都占16位,long类型占32位。后来,Windows和苹果系统都使用16位储存short类型,32位储存int类型和long类型(使用32位可以表示的整数数值超过20亿)。现在,计算机普遍使用64位处理器,为了储存64位的整数,才引入了long long类型。
现在,个人计算机上最常见的设置是,long long占64位,long占32位,short占16位,int占16位或32位(依计算机的自然字长而定)。原则上,这4种类型代表4种不同的大小,但是在实际使用中,有些类型之间通常有重叠。
C标准对基本数据类型只规定了允许的最小大小。对于16位机,short和int的最小取值范围是[−32767,32767];对于32位机,long的最小取值范围是[−2147483647,2147483647]。对于unsigned short和unsigned int,最小取值范围是[0,65535];对于unsigned long,最小取值范围是[0,4294967295]。long long类型是为了支持64位的需求,最小取值范围是[−9223372036854775807,9223372036854775807];unsigned long long的最小取值范围是[0,18446744073709551615]。如果要开支票,这个数是一千八百亿亿六千七百四十四万亿零七百三十七亿零九百五十五万一千六百一十五。但是,谁会去数?
int类型那么多,应该如何选择?首先,考虑unsigned类型。这种类型的数常用于计数,因为计数不用负数。而且,unsigned类型可以表示更大的正数。
如果一个数超出了int类型的取值范围,且在long类型的取值范围内时,使用long类型。然而,对于那些long占用的空间比int大的系统,使用long类型会减慢运算速度。因此,如非必要,请不要使用long类型。另外要注意一点:如果在long类型和int类型占用空间相同的机器上编写代码,当确实需要32位的整数时,应使用long类型而不是int类型,以便把程序移植到16位机后仍然可以正常工作。类似地,如果确实需要64位的整数,应使用long long类型。
如果在int设置为32位的系统中要使用16位的值,应使用short类型以节省存储空间。通常,只有当程序使用相对于系统可用内存较大的整型数组时,才需要重点考虑节省空间的问题。使用short类型的另一个原因是,计算机中某些组件使用的硬件寄存器是16位。
3.long常量和long long常量
通常,程序代码中使用的数字(如,2345)都被储存为int类型。如果使用1000000这样的大数字,超出了int类型能表示的范围,编译器会将其视为long int类型(假设这种类型可以表示该数字)。如果数字超出long可表示的最大值,编译器则将其视为unsigned long类型。如果还不够大,编译器则将其视为long long或unsigned long long类型(前提是编译器能识别这些类型)。
八进制和十六进制常量被视为int类型。如果值太大,编译器会尝试使用unsigned int。如果还不够大,编译器会依次使用long、unsigned long、long long和unsigned long long类型。
有些情况下,需要编译器以long类型储存一个小数字。例如,编程时要显式使用IBM PC上的内存地址时。另外,一些C标准函数也要求使用long类型的值。要把一个较小的常量作为long类型对待,可以在值的末尾加上l(小写的L)或L后缀。使用L后缀更好,因为l看上去和数字1很像。因此,在int为16位、long为32位的系统中,会把7作为16位储存,把7L作为32位储存。l或L后缀也可用于八进制和十六进制整数,如020L和0x10L。
类似地,在支持long long类型的系统中,也可以使用ll或LL后缀来表示long long类型的值,如3LL。另外,u或U后缀表示unsigned long long,如5ull、10LLU、6LLU或9Ull。
整数溢出
如果整数超出了相应类型的取值范围会怎样?下面分别将有符号类型和无符号类型的整数设置为比最大值略大,看看会发生什么(printf()函数使用%u说明显示unsigned int类型的值)。
/* toobig.c-- 超出系统允许的最大int值*/ #include <stdio.h> int main(void) { int i = 2147483647; unsigned int j = 4294967295; printf("%d %d %dn", i, i+1, i+2); printf("%u %u %un", j, j+1, j+2); return 0; }
在我们的系统下输出的结果是:
2147483647 -2147483648 -2147483647 4294967295 0 1
可以把无符号整数j看作是汽车的里程表。当达到它能表示的最大值时,会重新从起始点开始。整数i也是类似的情况。它们主要的区别是,在超过最大值时,unsigned int类型的变量j从0开始;而int类型的变量i则从−2147483648开始。注意,当i超出(溢出)其相应类型所能表示的最大值时,系统并未通知用户。因此,在编程时必须自己注意这类问题。
溢出行为是未定义的行为,C标准并未定义有符号类型的溢出规则。以上描述的溢出行为比较有代表性,但是也可能会出现其他情况。
4.打印short、long、long long和unsigned类型
打印unsigned int类型的值,使用%u转换说明;打印long类型的值,使用%ld转换说明。如果系统中int和long的大小相同,使用%d就行。但是,这样的程序被移植到其他系统(int和long类型的大小不同)中会无法正常工作。在x和o前面可以使用l前缀,%lx表示以十六进制格式打印long类型整数,%lo表示以八进制格式打印long类型整数。注意,虽然C允许使用大写或小写的常量后缀,但是在转换说明中只能用小写。
C语言有多种printf()格式。对于short类型,可以使用h前缀。%hd表示以十进制显示short类型的整数,%ho表示以八进制显示short类型的整数。h和l前缀都可以和u一起使用,用于表示无符号类型。例如,%lu表示打印unsigned long类型的值。程序清单3.4演示了一些例子。对于支持long long类型的系统,%lld和%llu分别表示有符号和无符号类型。第4章将详细介绍转换说明。
程序清单3.4 print2.c程序
/* print2.c--更多printf()的特性 */
#include <stdio.h>
int main(void)
{
unsigned int un = 3000000000; /* int为32位和short为16位的系统 */
short end = 200;
long big = 65537;
long long verybig = 12345678908642;
printf("un = %u and not %dn", un, un);
printf("end = %hd and %dn", end, end);
printf("big = %ld and not %hdn", big, big);
printf("verybig= %lld and not %ldn", verybig, verybig);
return 0;
}在特定的系统中输出如下(输出的结果可能不同):
un = 3000000000 and not -1294967296
end = 200 and 200
big = 65537 and not 1
verybig= 12345678908642 and not 1942899938该例表明,使用错误的转换说明会得到意想不到的结果。第1行输出,对于无符号变量un,使用%d会生成负值!其原因是,无符号值3000000000和有符号值−129496296在系统内存中的内部表示完全相同(详见第15章)。因此,如果告诉printf()该数是无符号数,它打印一个值;如果告诉它该数是有符号数,它将打印另一个值。在待打印的值大于有符号值的最大值时,会发生这种情况。对于较小的正数(如96),有符号和无符号类型的存储、显示都相同。
第2行输出,对于short类型的变量end,在printf()中无论指定以short类型(%hd)还是int类型(%d)打印,打印出来的值都相同。这是因为在给函数传递参数时,C编译器把short类型的值自动转换成int类型的值。你可能会提出疑问:为什么要进行转换?h修饰符有什么用?第1个问题的答案是,int类型被认为是计算机处理整数类型时最高效的类型。因此,在short和int类型的大小不同的计算机中,用int类型的参数传递速度更快。第2个问题的答案是,使用h修饰符可以显示较大整数被截断成short类型值的情况。第 3 行输出就演示了这种情况。把 65537 以二进制格式写成一个 32 位数是00000000000000010000000000000001。使用%hd,printf()只会查看后16位,所以显示的值是1。与此类似,输出的最后一行先显示了verybig的完整值,然后由于使用了%ld,printf()只显示了储存在后32位的值。
本章前面介绍过,程序员必须确保转换说明的数量和待打印值的数量相同。以上内容也提醒读者,程序员还必须根据待打印值的类型使用正确的转换说明。
提示
匹配printf()说明符的类型
在使用printf()函数时,切记检查每个待打印值都有对应的转换说明,还要检查转换说明的类型是否与待打印值的类型相匹配。
3.4.3 使用字符:char类型
char类型用于储存字符(如,字母或标点符号),但是从技术层面看,char是整数类型。因为char类型实际上储存的是整数而不是字符。计算机使用数字编码来处理字符,即用特定的整数表示特定的字符。美国最常用的编码是ASCII编码,本书也使用此编码。例如,在ASCII码中,整数65代表大写字母A。因此,储存字母A实际上储存的是整数65(许多IBM的大型主机使用另一种编码——EBCDIC,其原理相同。另外,其他国家的计算机系统可能使用完全不同的编码)。
标准ASCII码的范围是0~127,只需7位二进制数即可表示。通常,char类型被定义为8位的存储单元,因此容纳标准ASCII码绰绰有余。许多其他系统(如IMB PC和苹果Macs)还提供扩展ASCII码,也在8位的表示范围之内。一般而言,C语言会保证char类型足够大,以储存系统(实现C语言的系统)的基本字符集。
许多字符集都超过了127,甚至多于255。例如,日本汉字(kanji)字符集。商用的统一码(Unicode)创建了一个能表示世界范围内多种字符集的系统,目前包含的字符已超过110000个。国际标准化组织(ISO)和国际电工技术委员会(IEC)为字符集开发了ISO/IEC 10646标准。统一码标准也与ISO/IEC 10646标准兼容。
C语言把1字节定义为char类型占用的位(bit)数,因此无论是16位还是32位系统,都可以使用char类型。
1.声明char类型变量
char类型变量的声明方式与其他类型变量的声明方式相同。下面是一些例子:
char response;
char itable, latan;以上声明创建了3个char类型的变量:response、itable和latan。
2.字符常量和初始化
如果要把一个字符常量初始化为字母A,不必背下ASCII码,用计算机语言很容易做到。通过以下初始化把字母A赋给grade即可:
char grade = 'A';在C语言中,用单引号括起来的单个字符被称为字符常量(character constant)。编译器一发现'A',就会将其转换成相应的代码值。单引号必不可少。下面还有一些其他的例子:
char broiled; /* 声明一个char类型的变量 */
broiled = 'T'; /* 为其赋值,正确 */
broiled = T; /* 错误!此时T是一个变量 */
broiled = "T"; /* 错误!此时"T"是一个字符串 */如上所示,如果省略单引号,编译器认为T是一个变量名;如果把T用双引号括起来,编译器则认为"T"是一个字符串。字符串的内容将在第4章中介绍。
实际上,字符是以数值形式储存的,所以也可使用数字代码值来赋值:
char grade = 65; /* 对于ASCII,这样做没问题,但这是一种不好的编程风格 */在本例中,虽然65是int类型,但是它在char类型能表示的范围内,所以将其赋值给grade没问题。由于65是字母A对应的ASCII码,因此本例是把A赋给grade。注意,能这样做的前提是系统使用ASCII码。其实,用'A'代替65才是较为妥当的做法,这样在任何系统中都不会出问题。因此,最好使用字符常量,而不是数字代码值。
奇怪的是,C语言将字符常量视为int类型而非char类型。例如,在int为32位、char为8位的ASCII系统中,有下面的代码:
char grade = 'B';本来'B'对应的数值66储存在32位的存储单元中,现在却可以储存在8位的存储单元中(grade)。利用字符常量的这种特性,可以定义一个字符常量'FATE',即把4个独立的8位ASCII码储存在一个32位存储单元中。如果把这样的字符常量赋给char类型变量grade,只有最后8位有效。因此,grade的值是'E'。
3.非打印字符
单引号只适用于字符、数字和标点符号,浏览ASCII表会发现,有些ASCII字符打印不出来。例如,一些代表行为的字符(如,退格、换行、终端响铃或蜂鸣)。C语言提供了3种方法表示这些字符。
第1种方法前面介绍过——使用ASCII码。例如,蜂鸣字符的ASCII值是7,因此可以这样写:
char beep = 7;第2种方法是,使用特殊的符号序列表示一些特殊的字符。这些符号序列叫作转义序列(escape sequence)。表3.2列出了转义序列及其含义。
把转义序列赋给字符变量时,必须用单引号把转义序列括起来。例如,假设有下面一行代码:
char nerf = 'n';稍后打印变量nerf的效果是,在打印机或屏幕上另起一行。
表3.2 转义序列
| 转义序列 | 含义 |
| a | 警报(ANSI C) |
| b | 退格 |
| f | 换页 |
| n | 换行 |
| r | 回车 |
| t | 水平制表符 |
| v | 垂直制表符 |
| 反斜杠() | |
| ' | 单引号 |
| " | 双引号 |
| ? | 问号 |
| �oo | 八进制值(oo必须是有效的八进制数,即每个o可表示0~7中的一个数) |
| xhh | 十六进制值(hh必须是有效的十六进制数,即每个h可表示0~f中的一个数) |
现在,我们来仔细分析一下转义序列。使用C90新增的警报字符(a)是否能产生听到或看到的警报,取决于计算机的硬件,蜂鸣是最常见的警报(在一些系统中,警报字符不起作用)。C标准规定警报字符不得改变活跃位置。标准中的活跃位置(active position)指的是显示设备(屏幕、电传打字机、打印机等)中下一个字符将出现的位置。简而言之,平时常说的屏幕光标位置就是活跃位置。在程序中把警报字符输出在屏幕上的效果是,发出一声蜂鸣,但不会移动屏幕光标。
接下来的转义字符b、f、n、r、t和v是常用的输出设备控制字符。了解它们最好的方式是查看它们对活跃位置的影响。换页符(f)把活跃位置移至下一页的开始处;换行符(n)把活跃位置移至下一行的开始处;回车符(r)把活跃位置移动到当前行的开始处;水平制表符(t)将活跃位置移至下一个水平制表点(通常是第1个、第9个、第17个、第25个等字符位置);垂直制表符(v)把活跃位置移至下一个垂直制表点。
这些转义序列字符不一定在所有的显示设备上都起作用。例如,换页符和垂直制表符在PC屏幕上会生成奇怪的符号,光标并不会移动。只有将其输出到打印机上时才会产生前面描述的效果。
接下来的3个转义序列(、'、")用于打印、'、"字符(由于这些字符用于定义字符常量,是printf()函数的一部分,若直接使用它们会造成混乱)。如果打印下面一行内容:
Gramps sez, "a is a backslash."应这样编写代码:
printf("Gramps sez, "a is a backslash."n");表3.2中的最后两个转义序列(�oo和xhh)是ASCII码的特殊表示。如果要用八进制ASCII码表示一个字符,可以在编码值前面加一个反斜杠()并用单引号括起来。例如,如果编译器不识别警报字符(a),可以使用ASCII码来代替:
beep = '�07';可以省略前面的0,'�7'甚至'7'都可以。即使没有前缀0,编译器在处理这种写法时,仍会解释为八进制。
从C90开始,不仅可以用十进制、八进制形式表示字符常量,C语言还提供了第3种选择——用十六进制形式表示字符常量,即反斜杠后面跟一个x或X,再加上1~3位十六进制数字。例如,Ctrl+P字符的ASCII十六进制码是10(相当于十进制的16),可表示为'x10'或'x010'。图3.5列出了一些整数类型的不同进制形式。
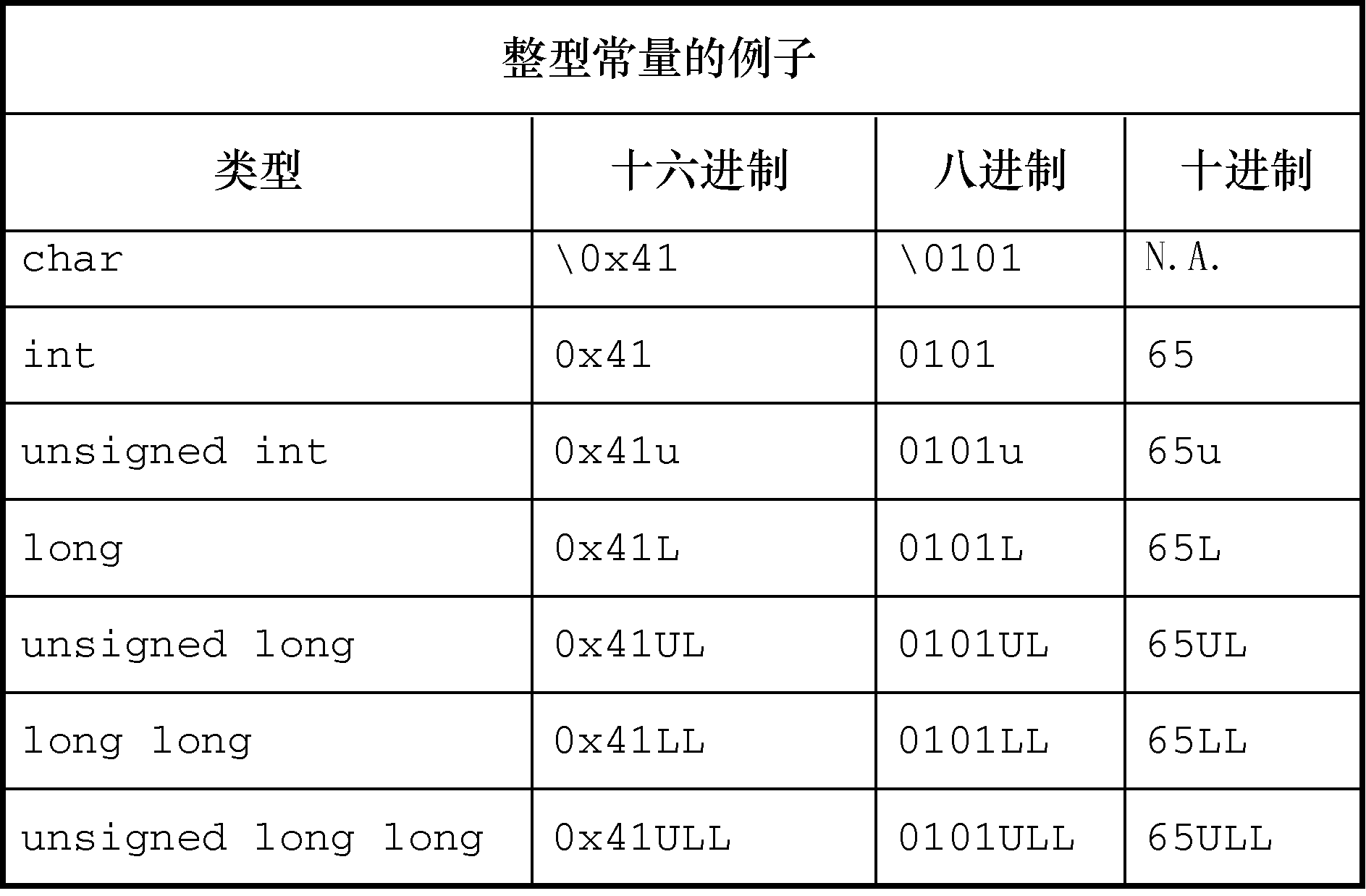
图3.5 int系列类型的常量写法示例
使用ASCII码时,注意数字和数字字符的区别。例如,字符4对应的ASCII码是52。'4'表示字符4,而不是数值4。
关于转义序列,读者可能有下面3个问题。
- 上面最后一个例子(printf("Gramps sez, "a is a backslash."n");),为何没有用单引号把转义序列括起来?无论是普通字符还是转义序列,只要是双引号括起来的字符集合,就无需用单引号括起来。双引号中的字符集合叫作字符串(详见第4章)。注意,该例中的其他字符(G、r、a、m、p、s等)都没有用单引号括起来。与此类似,printf("Hello!�07n");将打印Hello!并发出一声蜂鸣,而printf("Hello!7n");则打印Hello!7。不是转义序列中的数字将作为普通字符被打印出来。
- 何时使用ASCII码?何时使用转义序列?如果要在转义序列(假设使用'f')和ASCII码('�14')之间选择,请选择前者(即'f')。这样的写法不仅更好记,而且可移植性更高。'f'在不使用ASCII码的系统中,仍然有效。
- 如果要使用ASCII码,为何要写成'�32'而不是032?首先,'�32'能更清晰地表达程序员使用字符编码的意图。其次,类似�32这样的转义序列可以嵌入C的字符串中,如printf("Hello!�07n");中就嵌入了�07。
4.打印字符
printf()函数用%c指明待打印的字符。前面介绍过,一个字符变量实际上被储存为1字节的整数值。因此,如果用%d转换说明打印char类型变量的值,打印的是一个整数。而%c转换说明告诉printf()打印该整数值对应的字符。程序清单3.5演示了打印char类型变量的两种方式。
程序清单3.5 charcode.c程序
/* charcode.c-显示字符的代码编号 */
#include <stdio.h>
int main(void)
{
char ch;
printf("Please enter a character.n");
scanf("%c", &ch); /* 用户输入字符 */
printf("The code for %c is %d.n", ch, ch);
return 0;
}运行该程序后,输出示例如下:
Please enter a character.
C
The code for C is 67.运行该程序时,在输入字母后不要忘记按下Enter或Return键。随后,scanf()函数会读取用户输入的字符,&符号表示把输入的字符赋给变量ch。接着,printf()函数打印ch的值两次,第1次打印一个字符(对应代码中的%c),第2次打印一个十进制整数值(对应代码中的%d)。注意,printf()函数中的转换说明决定了数据的显示方式,而不是数据的储存方式(见图3.6)。

图3.6 数据显示和数据存储
5.有符号还是无符号
有些C编译器把char实现为有符号类型,这意味着char可表示的范围是-128~127。而有些C编译器把char实现为无符号类型,那么char可表示的范围是0~255。请查阅相应的编译器手册,确定正在使用的编译器如何实现char类型。或者,可以查阅limits.h头文件。下一章将详细介绍头文件的内容。
根据C90标准,C语言允许在关键字char前面使用signed或unsigned。这样,无论编译器默认char是什么类型,signed char表示有符号类型,而unsigned char表示无符号类型。这在用char类型处理小整数时很有用。如果只用char处理字符,那么char前面无需使用任何修饰符。
3.4.4 _Bool类型
C99标准添加了_Bool类型,用于表示布尔值,即逻辑值true和false。因为C语言用值1表示true,值0表示false,所以_Bool类型实际上也是一种整数类型。但原则上它仅占用1位存储空间,因为对0和1而言,1位的存储空间足够了。
程序通过布尔值可选择执行哪部分代码。我们将在第6章和第7章中详述相关内容。
3.4.5 可移植类型:stdint.h和inttypes.h
C语言提供了许多有用的整数类型。但是,某些类型名在不同系统中的功能不一样。C99新增了两个头文件stdint.h和inttypes.h,以确保C语言的类型在各系统中的功能相同。
C语言为现有类型创建了更多类型名。这些新的类型名定义在stdint.h头文件中。例如,int32_t表示32位的有符号整数类型。在使用32位int的系统中,头文件会把int32_t作为int的别名。不同的系统也可以定义相同的类型名。例如,int为16位、long为32位的系统会把int32_t作为long的别名。然后,使用int32_t类型编写程序,并包含stdint.h头文件时,编译器会把int或long替换成与当前系统匹配的类型。
上面讨论的类型别名是精确宽度整数类型(exact-width integer type)的示例。int32_t表示整数类型的宽度正好是32位。但是,计算机的底层系统可能不支持。因此,精确宽度整数类型是可选项。
如果系统不支持精确宽度整数类型怎么办?C99和C11提供了第2类别名集合。一些类型名保证所表示的类型一定是至少有指定宽度的最小整数类型。这组类型集合被称为最小宽度类型(minimum width type)。例如,int_least8_t是可容纳8位有符号整数值的类型中宽度最小的类型的一个别名。如果某系统的最小整数类型是16位,可能不会定义int8_t类型。尽管如此,该系统仍可使用int_least8_t类型,但可能把该类型实现为16位的整数类型。
当然,一些程序员更关心速度而非空间。为此,C99和C11定义了一组可使计算达到最快的类型集合。这组类型集合被称为最快最小宽度类型(fastst minimum width type)。例如,int_fast8_t被定义为系统中对8位有符号值而言运算最快的整数类型的别名。
另外,有些程序员需要系统的最大整数类型。为此,C99定义了最大的有符号整数类型intmax_t,可储存任何有效的有符号整数值。类似地,uintmax_t表示最大的无符号整数类型。顺带一提,这些类型有可能比long long和unsigned long类型更大,因为C编译器除了实现标准规定的类型以外,还可利用C语言实现其他类型。例如,一些编译器在标准引入long long类型之前,已提前实现了该类型。
C99和C11不仅提供可移植的类型名,还提供相应的输入和输出。例如,printf()打印特定类型时要求与相应的转换说明匹配。如果要打印int32_t类型的值,有些定义使用%d,而有些定义使用%ld,怎么办?C标准针对这一情况,提供了一些字符串宏(第4章中详细介绍)来显示可移植类型。例如,inttypes.h头文件中定义了PRId32字符串宏,代表打印32位有符号值的合适转换说明(如d或l)。程序清单3.6演示了一种可移植类型和相应转换说明的用法。
程序清单3.6 altnames.c程序
/* altnames.c -- 可移植整数类型名 */
#include <stdio.h>
#include <inttypes.h> // 支持可移植类型
int main(void)
{
int32_t me32; // me32是一个32位有符号整型变量
me32 = 45933945;
printf("First, assume int32_t is int: ");
printf("me32 = %dn", me32);
printf("Next, let's not make any assumptions.n");
printf("Instead, use a "macro" from inttypes.h: ");
printf("me32 = %" "d" "n", me32);
return 0;
}该程序最后一个printf()中,参数PRId32被定义在inttypes.h中的"d"替换,因而这条语句等价于:
printf(“me32 = %dn”, me32);在C语言中,可以把多个连续的字符串组合成一个字符串,所以这条语句又等价于:
printf("me32 = %dn", me32);下面是该程序的输出,注意,程序中使用了"转义序列来显示双引号:
First, assume int32_t is int: me32 = 45933945
Next, let's not make any assumptions.
Instead, use a "macro" from inttypes.h: me32 = 45933945篇幅有限,无法介绍扩展的所有整数类型。本节主要是为了让读者知道,在需要时可进行这种级别的类型控制。附录B中的参考资料VI“扩展的整数类型”介绍了完整的inttypes.h和stdint.h头文件。
注意
对C99/C11的支持
C语言发展至今,虽然ISO已发布了C11标准,但是编译器供应商对C99的实现程度却各不相同。在本书第6版的编写过程中,一些编译器仍未实现inttypes.h头文件及其相关功能。
3.4.6 float、double和long double
各种整数类型对大多数软件开发项目而言够用了。然而,面向金融和数学的程序经常使用浮点数。C语言中的浮点类型有float、double和long double类型。它们与FORTRAN和Pascal中的real类型一致。前面提到过,浮点类型能表示包括小数在内更大范围的数。浮点数的表示类似于科学记数法(即用小数乘以10的幂来表示数字)。该记数系统常用于表示非常大或非常小的数。表3.3列出了一些示例。
表3.3 记数法示例
| 数字 | 科学记数法 | 指数记数法 |
| 1000000000 | 1.0×109 | 1.0e9 |
| 123000 | 1.23×105 | 1.23e5 |
| 322.56 | 3.2256×102 | 3.2256e2 |
| 0.000056 | 5.6×10-5 | 5.6e-5 |
第1列是一般记数法;第2列是科学记数法;第3列是指数记数法(或称为e记数法),这是科学记数法在计算机中的写法,e后面的数字代表10的指数。图3.7演示了更多的浮点数写法。
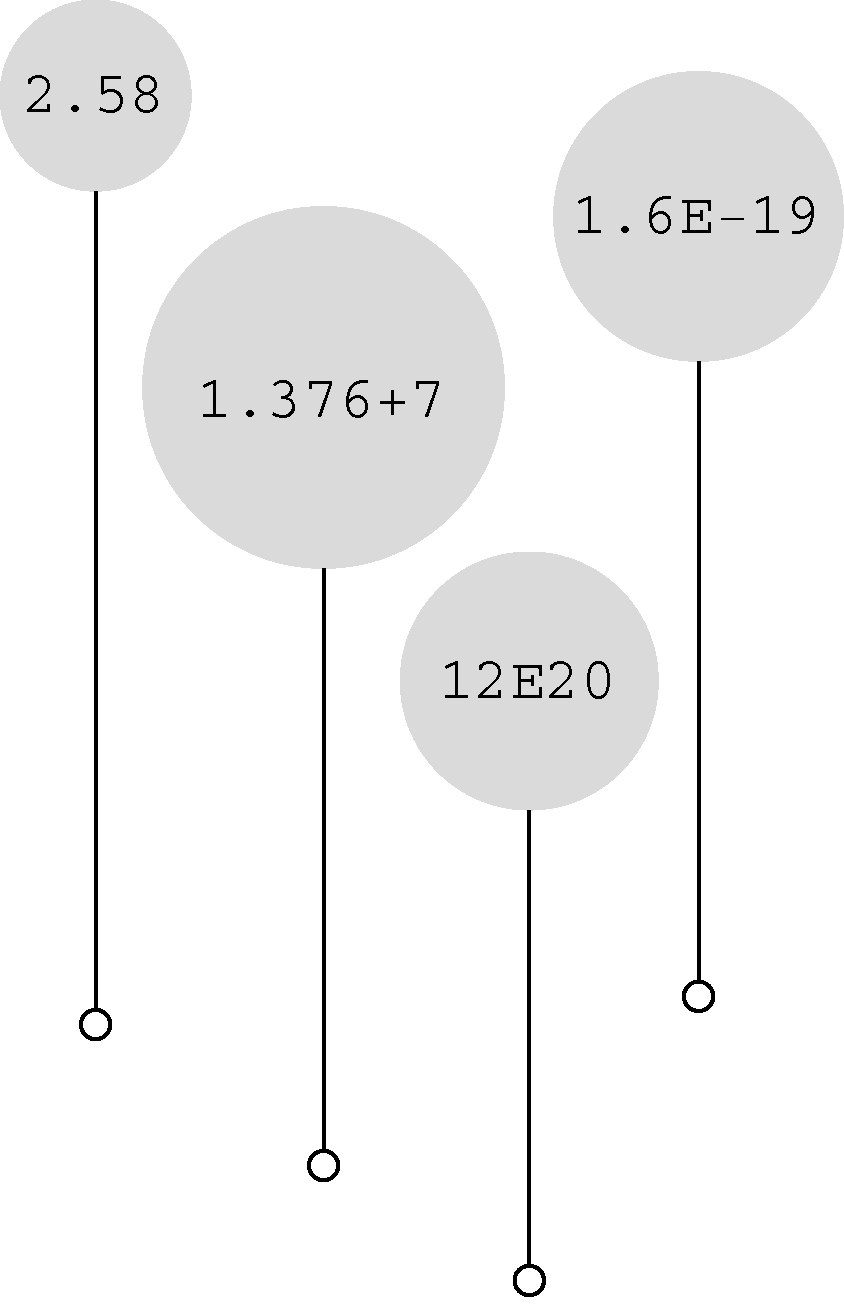
图3.7 更多浮点数写法示例
C标准规定,float类型必须至少能表示6位有效数字,且取值范围至少是10-37~10+37。前一项规定指float类型必须能够表示33.333333的前6位数字,而不是精确到小数点后6位数字。后一项规定用于方便地表示诸如太阳质量(2.0e30千克)、一个质子的电荷量(1.6e-19库仑)或国家债务之类的数字。通常,系统储存一个浮点数要占用32位。其中8位用于表示指数的值和符号,剩下24位用于表示非指数部分(也叫作尾数或有效数)及其符号。
C语言提供的另一种浮点类型是double(意为双精度)。double类型和float类型的最小取值范围相同,但至少必须能表示10位有效数字。一般情况下,double占用64位而不是32位。一些系统将多出的32位全部用来表示非指数部分,这不仅增加了有效数字的位数(即提高了精度),而且还减少了舍入误差。另一些系统把其中的一些位分配给指数部分,以容纳更大的指数,从而增加了可表示数的范围。无论哪种方法,double类型的值至少有13位有效数字,超过了标准的最低位数规定。
C语言的第3种浮点类型是long double,以满足比double类型更高的精度要求。不过,C只保证long double类型至少与double类型的精度相同。
1.声明浮点型变量
浮点型变量的声明和初始化方式与整型变量相同,下面是一些例子:
float noah, jonah;
double trouble;
float planck = 6.63e-34;
long double gnp;2.浮点型常量
在代码中,可以用多种形式书写浮点型常量。浮点型常量的基本形式是:有符号的数字(包括小数点),后面紧跟e或E,最后是一个有符号数表示10的指数。下面是两个有效的浮点型常量:
-1.56E+12
2.87e-3正号可以省略。可以没有小数点(如,2E5)或指数部分(如,19.28),但是不能同时省略两者。可以省略小数部分(如,3.E16)或整数部分(如,.45E-6),但是不能同时省略两者。下面是更多的有效浮点型常量示例:
3.14159
.2
4e16
.8E-5
100.不要在浮点型常量中间加空格:1.56 E+12(错误!)
默认情况下,编译器假定浮点型常量是double类型的精度。例如,假设some是float类型的变量,编写下面的语句:
some = 4.0 * 2.0;通常,4.0和2.0被储存为64位的double类型,使用双精度进行乘法运算,然后将乘积截断成float类型的宽度。这样做虽然计算精度更高,但是会减慢程序的运行速度。
在浮点数后面加上f或F后缀可覆盖默认设置,编译器会将浮点型常量看作float类型,如2.3f和9.11E9F。使用l或L后缀使得数字成为long double类型,如54.3l和4.32L。注意,建议使用L后缀,因为字母l和数字1很容易混淆。没有后缀的浮点型常量是double类型。
C99标准添加了一种新的浮点型常量格式——用十六进制表示浮点型常量,即在十六进制数前加上十六进制前缀(0x或0X),用p和P分别代替e和E,用2的幂代替10的幂(即,p计数法)。如下所示:
0xa.1fp10十六进制a等于十进制10,.1f是1/16加上15/256(十六进制f等于十进制15),p10是210或1024。0xa.1fp10表示的值是(10 + 1/16 + 15/256)×1024(即,十进制10364.0)。
注意,并非所有的编译器都支持C99的这一特性。
3.打印浮点值
printf()函数使用%f转换说明打印十进制记数法的float和double类型浮点数,用%e打印指数记数法的浮点数。如果系统支持十六进制格式的浮点数,可用a和A分别代替e和E。打印long double类型要使用%Lf、%Le或%La转换说明。给那些未在函数原型中显式说明参数类型的函数(如,printf())传递参数时,C编译器会把float类型的值自动转换成double类型。程序清单3.7演示了这些特性。
程序清单3.7 showf_pt.c程序
/* showf_pt.c -- 以两种方式显示float类型的值 */
#include <stdio.h>
int main(void)
{
float aboat = 32000.0;
double abet = 2.14e9;
long double dip = 5.32e-5;
printf("%f can be written %en", aboat, aboat);
// 下一行要求编译器支持C99或其中的相关特性
printf("And it's %a in hexadecimal, powers of 2 notationn", aboat);
printf("%f can be written %en", abet, abet);
printf("%Lf can be written %Len", dip, dip);
return 0;
}该程序的输出如下,前提是编译器支持C99/C11:
32000.000000 can be written 3.200000e+04
And it's 0x1.f4p+14 in hexadecimal, powers of 2 notation
2140000000.000000 can be written 2.140000e+09
0.000053 can be written 5.320000e-05该程序示例演示了默认的输出效果。下一章将介绍如何通过设置字段宽度和小数位数来控制输出格式。
4.浮点值的上溢和下溢
假设系统的最大float类型值是3.4E38,编写如下代码:
float toobig = 3.4E38 * 100.0f;
printf("%en", toobig);会发生什么?这是一个上溢(overflow)的示例。当计算导致数字过大,超过当前类型能表达的范围时,就会发生上溢。这种行为在过去是未定义的,不过现在C语言规定,在这种情况下会给toobig赋一个表示无穷大的特定值,而且printf()显示该值为inf或infinity(或者具有无穷含义的其他内容)。
当对一个很小的数做除法时,情况更为复杂。回忆一下,float类型的数以指数和尾数部分来储存。存在这样一个数,它的指数部分是最小值,即由全部可用位表示的最小尾数值。该数字是float类型能用全部精度表示的最小数字。现在把它除以2。通常,这个操作会减小指数部分,但是假设的情况中,指数已经是最小值了。所以计算机只好把尾数部分的位向右移,空出第1个二进制位,并丢弃最后一个二进制数。以十进制为例,把一个有4位有效数字的数(如,0.1234E-10)除以10,得到的结果是0.0123E-10。虽然得到了结果,但是在计算过程中却损失了原末尾有效位上的数字。这种情况叫作下溢(underflow)。C语言把损失了类型全精度的浮点值称为低于正常的(subnormal)浮点值。因此,把最小的正浮点数除以2将得到一个低于正常的值。如果除以一个非常大的值,会导致所有的位都为0。现在,C库已提供了用于检查计算是否会产生低于正常值的函数。
还有另一个特殊的浮点值NaN(not a number的缩写)。例如,给asin()函数传递一个值,该函数将返回一个角度,该角度的正弦就是传入函数的值。但是正弦值不能大于1,因此,如果传入的参数大于1,该函数的行为是未定义的。在这种情况下,该函数将返回NaN值,printf()函数可将其显示为nan、NaN或其他类似的内容。
浮点数舍入错误
给定一个数,加上1,再减去原来给定的数,结果是多少?你一定认为是1。但是,下面的浮点运算给出了不同的答案:
/* floaterr.c--演示舍入错误 */ #include <stdio.h> int main(void) { float a,b; b = 2.0e20 + 1.0; a = b - 2.0e20; printf("%f n", a); return 0; }
该程序的输出如下:
0.000000 ←Linux系统下的老式gcc -13584010575872.000000 ←Turbo C 1.5 4008175468544.000000 ←XCode 4.5、Visual Studio 2012、当前版本的gcc
得出这些奇怪答案的原因是,计算机缺少足够的小数位来完成正确的运算。2.0e20是2后面有20个0。如果把该数加1,那么发生变化的是第21位。要正确运算,程序至少要储存21位数字。而float类型的数字通常只能储存按指数比例缩小或放大的6或7位有效数字。在这种情况下,计算结果一定是错误的。另一方面,如果把2.0e20改成2.0e4,计算结果就没问题。因为2.0e4加1只需改变第5位上的数字,float类型的精度足够进行这样的计算。
浮点数表示法
上一个方框中列出了由于计算机使用的系统不同,一个程序有不同的输出。原因是,根据前面介绍的知识,实现浮点数表示法的方法有多种。为了尽可能地统一实现,电子和电气工程师协会(IEEE)为浮点数计算和表示法开发了一套标准。现在,许多硬件浮点单元都采用该标准。2011年,该标准被ISO/IEC/IEEE 60559:2011标准收录。该标准作为C99和C11的可选项,符合硬件要求的平台可开启。floaterr.c程序的第3个输出示例即是支持该浮点标准的系统显示的结果。支持C标准的编译器还包含捕获异常问题的工具。详见附录B.5,参考资料V。
3.4.7 复数和虚数类型
许多科学和工程计算都要用到复数和虚数。C99标准支持复数类型和虚数类型,但是有所保留。一些独立实现,如嵌入式处理器的实现,就不需要使用复数和虚数(VCR芯片就不需要复数)。一般而言,虚数类型都是可选项。C11标准把整个复数软件包都作为可选项。
简而言之,C语言有3种复数类型:float _Complex、double _Complex和long double _Complex。例如,float _Complex类型的变量应包含两个float类型的值,分别表示复数的实部和虚部。类似地,C语言的3种虚数类型是float _Imaginary、double _Imaginary和long double _Imaginary。
如果包含complex.h头文件,便可用complex代替_Complex,用imaginary代替_Imaginary,还可以用I代替-1的平方根。
为何C标准不直接用complex作为关键字来代替_Complex,而要添加一个头文件(该头文件中把complex定义为_Complex)?因为标准委员会考虑到,如果使用新的关键字,会导致以该关键字作为标识符的现有代码全部失效。例如,之前的C99,许多程序员已经使用struct complex定义一个结构来表示复数或者心理学程序中的心理状况(关键字struct用于定义能储存多个值的结构,详见第14章)。让complex成为关键字会导致之前的这些代码出现语法错误。但是,使用struct _Complex的人很少,特别是标准使用首字母是下划线的标识符作为预留字以后。因此,标准委员会选定_Complex作为关键字,在不用考虑名称冲突的情况下可选择使用complex。
3.4.8 其他类型
现在已经介绍完C语言的所有基本数据类型。有些人认为这些类型实在太多了,但有些人觉得还不够用。注意,虽然C语言没有字符串类型,但也能很好地处理字符串。第4章将详细介绍相关内容。
C语言还有一些从基本类型衍生的其他类型,包括数组、指针、结构和联合。尽管后面章节中会详细介绍这些类型,但是本章的程序示例中已经用到了指针〔指针(pointer)指向变量或其他数据对象位置〕。例如,在scanf()函数中用到的前缀&,便创建了一个指针,告诉scanf()把数据放在何处。
小结:基本数据类型
关键字:
基本数据类型由11个关键字组成:int、long、short、unsigned、char、float、double、signed、_Bool、_Complex和_Imaginary。
有符号整型:
有符号整型可用于表示正整数和负整数。
int ——系统给定的基本整数类型。C语言规定int类型不小于16位。short或short int ——最大的short类型整数小于或等于最大的int类型整数。C语言规定short类型至少占16位。long或long int ——该类型可表示的整数大于或等于最大的int类型整数。C语言规定long类型至少占32位。long long或long long int ——该类型可表示的整数大于或等于最大的long类型整数。long long类型至少占64位。
一般而言,long类型占用的内存比short类型大,int类型的宽度要么和long类型相同,要么和short类型相同。例如,旧DOS系统的PC提供16位的short和int,以及32位的long;Windows 95系统提供16位的short以及32位的int和long。
无符号整型:
无符号整型只能用于表示零和正整数,因此无符号整型可表示的正整数比有符号整型的大。在整型类型前加上关键字unsigned表明该类型是无符号整型:unsigned int、unsigned long、unsigned short。单独的unsigned相当于unsigned int。
字符类型:
可打印出来的符号(如A、&和+)都是字符。根据定义,char类型表示一个字符要占用1字节内存。出于历史原因,1字节通常是8位,但是如果要表示基本字符集,也可以是16位或更大。
char ——字符类型的关键字。有些编译器使用有符号的char,而有些则使用无符号的char。在需要时,可在char前面加上关键字signed或unsigned来指明具体使用哪一种类型。
布尔类型:
布尔值表示true和false。C语言用1表示true,0表示false。
_Bool ——布尔类型的关键字。布尔类型是无符号int类型,所占用的空间只要能储存0或1即可。
实浮点类型:
实浮点类型可表示正浮点数和负浮点数。
float ——系统的基本浮点类型,可精确表示至少6位有效数字。double ——储存浮点数的范围(可能)更大,能表示比float类型更多的有效数字(至少10位,通常会更多)和更大的指数。long double ——储存浮点数的范围(可能)比double更大,能表示比double更多的有效数字和更大的指数。
复数和虚数浮点数:
虚数类型是可选的类型。复数的实部和虚部类型都基于实浮点类型来构成:
float _Complexdouble _Complexlong double _Complexfloat _Imaginarydouble _Imaginarylong double _Imaginary
小结:如何声明简单变量
1.选择需要的类型。
2.使用有效的字符给变量起一个变量名。
3.按以下格式进行声明:
类型说明符 变量名;
类型说明符由一个或多个关键字组成。下面是一些示例:
int erest; unsigned short cash;
4.可以同时声明相同类型的多个变量,用逗号分隔各变量名,如下所示:
char ch, init, ans;
5.在声明的同时还可以初始化变量:
float mass = 6.0E24;
3.4.9 类型大小
如何知道当前系统的指定类型的大小是多少?运行程序清单3.8,会列出当前系统的各类型的大小。
程序清单3.8 typesize.c程序
/* typesize.c -- 打印类型大小 */
#include <stdio.h>
int main(void)
{
/* C99为类型大小提供%zd转换说明 */
printf("Type int has a size of %zd bytes.n", sizeof(int));
printf("Type char has a size of %zd bytes.n", sizeof(char));
printf("Type long has a size of %zd bytes.n", sizeof(long));
printf("Type long long has a size of %zd bytes.n",
sizeof(long long));
printf("Type double has a size of %zd bytes.n",
sizeof(double));
printf("Type long double has a size of %zd bytes.n",
sizeof(long double));
return 0;
}sizeof是C语言的内置运算符,以字节为单位给出指定类型的大小。C99和C11提供%zd转换说明匹配sizeof的返回类型[2]。一些不支持C99和C11的编译器可用%u或%lu代替%zd。
该程序的输出如下:
Type int has a size of 4 bytes.
Type char has a size of 1 bytes.
Type long has a size of 8 bytes.
Type long long has a size of 8 bytes.
Type double has a size of 8 bytes.
Type long double has a size of 16 bytes.该程序列出了6种类型的大小,你也可以把程序中的类型更换成感兴趣的其他类型。注意,因为C语言定义了char类型是1字节,所以char类型的大小一定是1字节。而在char类型为16位、double类型为64位的系统中,sizeof给出的double是4字节。在limits.h和float.h头文件中有类型限制的相关信息(下一章将详细介绍这两个头文件)。
顺带一提,注意该程序最后几行printf()语句都被分为两行,只要不在引号内部或一个单词中间断行,就可以这样写。
本文摘自《C Primer Plus(第6版)》中文版

- 经久不衰的C语言畅销经典教程
- 中文版累计销量近百万册
- 针对C11标准进行全面更新
本书详细讲解了C语言的基本概念和编程技巧。
全书共17章。第1章、第2章介绍了C语言编程的预备知识。第3章~第15章详细讲解了C语言的相关知识,包括数据类型、格式化输入/输出、运算符、表达式、语句、循环、字符输入和输出、函数、数组和指针、字符和字符串函数、内存管理、文件输入输出、结构、位操作等。第16章、第17章介绍C预处理器、C库和高级数据表示。本书以完整的程序为例,讲解C语言的知识要点和注意事项。每章末尾设计了大量复习题和编程练习,帮助读者巩固所学知识和提高实际编程能力。附录给出了各章复习题的参考答案和丰富的参考资料。
本书可作为C语言的教材,适用于需要系统学习C语言的初学者,也适用于巩固C语言知识或希望进一步提高编程技术的程序员。
相关推荐
-
想学c语言应该怎么学(c语言到底怎么学)
如何学习C语言,在学习C语言的时候一定要掌握什么知识?在这里我给大家写出了一点点小计划,不喜勿喷,谢谢! 一、要学习的书 《C Primer Plus》、《C缺陷和陷阱》、《C和指针》、《C专家编程》。 二、知识点学习 1....
-
基于stm32的c语言程序设计详解(STM32 嵌入式C语言教程)
随着单片机技术的发展,目前已经从8位机升级到32位机。编程语言也从汇编语言逐步变成以C语言为主,汇编为辅。 一、STM32简介 · STM32是由ST公司开发的32位微控制器,是继MCS51单片机(8位机)后又一款非常经典的单片...
-
printf和gets函数的实用技巧(c语言中gets函数怎么用)
Printf函数输出的格式与方法: 1、输出数字的时候存在宽度和精度,那对于数字而言,输出数字有如下几种情况: int a=456; printf("$%d$",a); 此时输出$456$ printf("$%5d$",a); 此时输出整型变量的宽度为5,比变量a...
-
c语言fact函数计算阶乘(用fact函数求阶乘之和)
各位Excel天天学的小伙伴们大家好,欢迎收看Excel天天学出品的excel2019函数公式大全课程。今天我们依旧要学习的是Excel函数中的数学函FACT函数。 FACT函数是计算阶乘的函数,在数学中我们计算阶乘的公式为:n!=nx(n...
-
简单的c语言程序画心(用c语言编程心形图案)
前言你以为C语言就是提供一种编译、处理低级存储器、产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言吗?你以为C语言就只是以一个标准规格写出的C语言程序可在许多电脑平台上进行编译,甚至包含一些...
-
c语言指针malloc使用格式(c语言malloc函数用法示例)
malloc就是memory allocate动态分配内存,当无法知道内存具体位置的时候,想要绑定真正的内存空间,就需要用到动态的分配内存,今天我们就来学习下malloc这个函数吧: 我们来了解下malloc函数的使用: 首先,包含mal...